Processamento de linguagem natural na detecção de fraudes em notas fiscais do município de São Paulo


Por Augusto Cezar Garcia Lozano e André Ippolito
1. Introdução
A Inteligência Artificial (IA) tem sido explorada para solucionar problemas em diversas áreas do conhecimento. No contexto da Administração Pública, a IA pode proporcionar automação e eficiência em tarefas rotineiras de planejamento e economia de recursos (Souza et al., 2022). As administrações tributárias enfrentam muitos desafios. Para cumprir suas missões institucionais, as autoridades fiscais podem aplicar a IA para aprimorar as auditorias fiscais (Nunes; Delgado, 2023).
A motivação para o uso de IA é perceptível no trabalho diário da Administração Tributária da cidade de São Paulo. No setor de fiscalização, a análise de notas fiscais eletrônicas (NFS-e) permite a verificação do comportamento de certos contribuintes. No preenchimento da NFS-e, são utilizados textos que descrevem serviços tributados em 5%, mas aplicam códigos de serviço com alíquota inferior, resultando em menor arrecadação.
Precisamos lidar com o grande volume de notas fiscais e contribuintes. Analisando o território brasileiro, as estatísticas indicam a emissão de 40,394 bilhões de notas fiscais desde 2006 para um total de 226,5 milhões de contribuintes (Receita Federal do Brasil 2024). No município de São Paulo, dados da Secretaria Municipal da Fazenda registraram, para o ano de 2023, 664.215.745 notas fiscais emitidas para um total de 825.013 contribuintes. A análise manual desse volume é custosa, e a tendência é que os contribuintes se aproveitem dessa dificuldade para fraudar a Receita Federal, como explicado anteriormente. Conjuntos de dados como o descrito são difíceis de processar, sendo considerados um problema de Big Data (SAS 2024a). Esse contexto exige análise automatizada, que possibilita decisões mais rápidas e cronogramas tributários mais assertivos, alavancando a arrecadação de impostos.
Isso motiva o uso de técnicas de IA e Big Data. O Processamento de Linguagem Natural (PLN, ou Natural Language Processing – NLP) fornece uma estrutura de técnicas para análise de texto (Jurafsky; Martin 2008). Assim, o objetivo deste trabalho é aplicar PLN para descobrir quais são os termos mais frequentes usados em descrições de serviços de tarifa mais alta, mas que também são usados em notas com códigos de serviço de tarifa mais baixa.
Foram desenvolvidos trabalhos relacionados à aplicação de PLN na detecção de fraudes em notas fiscais. Marinho (2023) realizou um estudo com 10.000 notas fiscais do Distrito Federal. Foram calculadas as similaridades entre o texto descritivo do produto na nota e a nomenclatura oficial da mercadoria pelo Mercosul. Notas fiscais com baixa similaridade foram consideradas inconsistentes, o que auxiliou a análise dos auditores. Darrazão et al. (2023) basearam seu estudo em um conjunto de notas fiscais do Piauí. No trabalho, partindo de uma lista de 1.000.506 notas, 200 foram selecionadas aleatoriamente e categorizadas manualmente. Algoritmos de classificação foram aplicados e os resultados avaliados. Santos (2022) desenvolveu um trabalho para classificar textos descritivos de notas fiscais. O banco de dados utilizado, com 30.000 notas fiscais, foi fornecido pelo Ministério Público da Paraíba. Uma amostra dos dados foi classificada manualmente. Técnicas de PLN foram aplicadas para classificar as categorias.
As soluções mais modernas dependem de trabalho manual e utilizam conjuntos de dados com representatividade reduzida em relação ao volume de notas fiscais existentes. Além disso, não foram encontrados estudos que visassem detectar fraudes no uso indevido de alíquotas de impostos e que considerassem a análise dos termos mais frequentes nas descrições de serviços.
2. Quadro Teórico
Nesta seção, são explicados os conceitos relacionados ao Hadoop e ao PLN (Processamento de Linguagem Natural).
2.1 Hadoop
O Hadoop (Apache Hadoop 2006) é um sistema que extrai, armazena e analisa grandes volumes de dados (SAS 2024b). De acordo com a Figura 1, a arquitetura do Hadoop é formada por uma rede de computadores que distribui o armazenamento e o processamento de dados (Machado 2017).
Figura 1 – Arquitetura do Hadoop
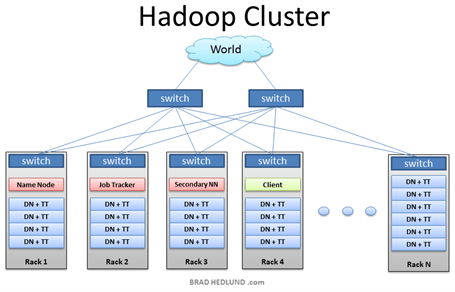
Fonte: Machado (2017).
É possível acoplar o componente Spark ao sistema Hadoop, conforme mostrado na Figura 2, o que complementa o sistema com streaming e IA (Techvidvan 2024).
Figura 2 – Integração entre Hadoop e Spark
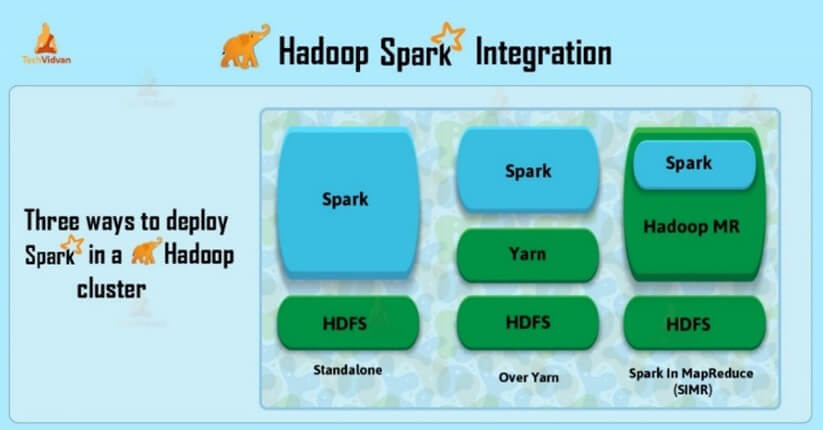
Fonte: Techvidvan (2024).
2.2 Processamento de Linguagem Natural
O PLN (Processamento de Linguagem Natural) (Jurafsky; Martin 2008) permite que os computadores realizem tarefas envolvendo a linguagem humana e se aplica a áreas como reconhecimento de fala e análise semântica (Steedman 1996).
2.2.1 Pré-processamento de texto
A primeira técnica utilizada em PLN é a tokenização, que divide um texto em unidades; estas podem ser palavras ou números (Manning; Schütze 1999). Uma vez que o texto é tokenizado, aplicam-se técnicas de redução de palavras, como stemming e lematização. Na primeira, prefixos e sufixos são eliminados. Na segunda, uma palavra é reduzida ao seu lema: por exemplo, a palavra ‘amigos’ torna-se ‘amigo’. Palavras que não são úteis, como artigos e preposições, são removidas e chamadas de stopwords.
2.2.2 Representação Vetorial
O modelo utilizado é o de saco de palavras, que cria um vetor com uma dimensão dada pelo número de palavras diferentes, armazenando em cada espaço do vetor a frequência da respectiva palavra (Feldman; Sanger 2006). Alguns modelos são baseados na coocorrência de palavras, utilizando uma matriz na qual cada linha é uma palavra e as colunas são documentos, sendo a célula da matriz a frequência da palavra por documento (Jurafsky; Martin 2008).
O modelo de frequência do termo-frequência inversa do documento (TF-IDF) baseia-se na coocorrência de palavras. O TF calcula a frequência com que um determinado termo t aparece em um documento d, e o IDF pondera essa frequência com base no número total de documentos e no número de documentos em que o termo aparece. O IDF é dado por:

3. Metodologia
Os estudos para solucionar o problema apresentado neste estudo começaram em 2019. Naquela época, a unidade de Inteligência Tributária possuía um computador e uma ferramenta visual com 2 GB de RAM. O tempo de processamento era de uma semana.
A solução atual representa uma evolução. Ela foi desenvolvida em um ambiente configurável, adequado para problemas de Big Data. A plataforma de desenvolvimento Jupyter (Jupyter, 2015) foi utilizada, juntamente com o sistema Hadoop. Rotinas de programação foram desenvolvidas nas linguagens Sqoop e Python para armazenar e preparar dados e modelar textos utilizando PLN (Processamento de Linguagem Natural). O ambiente foi configurado com 20 GB de RAM. Entre as vantagens, destacam-se a capacidade de distribuir o processamento e o armazenamento de dados e de desenvolver código flexível.
Os bancos de dados utilizados foram tabelas da NFS-e da Secretaria Municipal de Finanças de São Paulo, referentes ao período de 2019 a 2022. As etapas da solução seguem o fluxograma da Figura 1. Os seguintes passos foram realizados:
- Importe as notas fiscais com a alíquota de imposto mais alta para o sistema ADO Hadoop.
- Use o Spark para processar texto de serviços de anotações:
- Normalizar os termos para minúsculas.
- Remova os espaços em branco.
- Remova caracteres especiais, sinais de pontuação, acentos e palavras-chave.
- Radicalização e lematização.
- Crie uma tabela com as palavras obtidas e seus respectivos valores TF-IDF.
- Selecione as notas do código de taxa inferior que contenham os termos mais frequentes do código de taxa superior obtido no item 4. Os termos mais frequentes foram considerados os 100 termos com o maior valor TF-IDF.
Figura 1: Fluxograma das etapas da solução
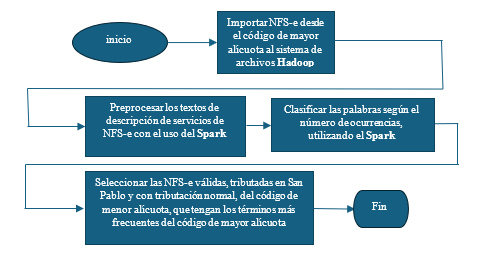
- -Importar NFS-e do código de alíquota mais alto para o sistema de arquivos Hadoop
- -Pré-processar os textos de descrição do serviço NFS-e usando o Spark
- -Classifique as palavras de acordo com o número de ocorrências usando o Spark.
- -Selecione as NFS-e válidas, tributadas em São Paulo e com alíquota normal de imposto de menor valor, que apresentem os termos mais frequentes da alíquota de maior valor.
4. Resultados e Discussão
Foram analisadas as transações relacionadas a impostos resultantes da aplicação da metodologia neste estudo. Observou-se uma tendência crescente de 2019 a 2022, período em que a metodologia foi aplicada. No total, foram realizadas 27 transações, sendo 23 concluídas e 4 em andamento, abrangendo 27 empresas, conforme ilustrado na Figura 1.
Gráfico 1 – Operações de controle emitidas
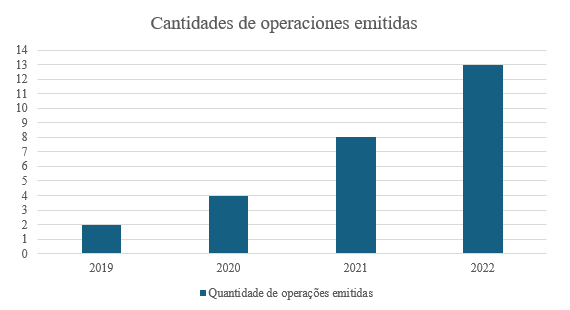
Fonte : Elaborado pelos autores (2024).
Os números relativos às notificações de infração são apresentados no Gráfico 2, sendo que 72% do valor total das notificações já foi pago. De acordo com o Gráfico 3, foram emitidas 249 notificações. Ao avaliar o percentual de quitação de impostos em relação ao faturamento da empresa, esse número chega a 65%.
Gráfico 2 – Valores das notificações de infração
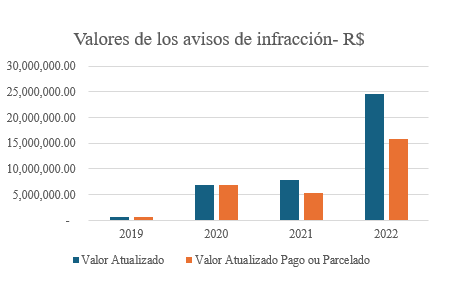
Fonte : Elaborado pelos autores (2024).
Gráfico 3 – Número de notificações de infração
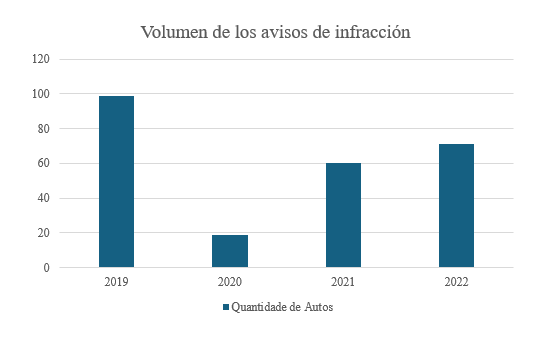
Fonte : Elaborado pelos autores (2024).
Em relação ao volume de notas analisadas, um total de 38.727.247 notas foram processadas. Essa análise foi dividida em dois grupos: um grupo de notas com taxas de imposto mais altas e outro de notas com taxas de imposto mais baixas. O Gráfico 4 mostra a tendência anual desses valores.
Gráfico 4 – Número de notas fiscais analisadas
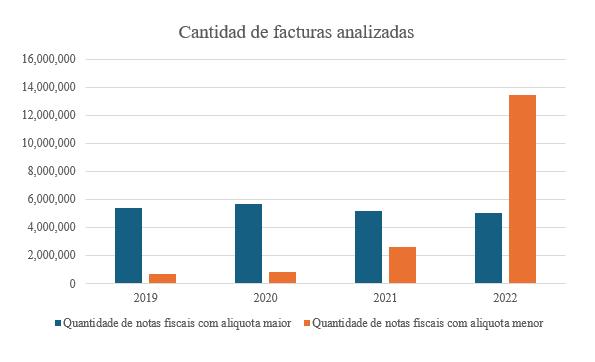
Fonte : Elaborado pelos autores (2024).
Analisou-se a evolução do ISS (Imposto Municipal sobre Serviços) pago pelos contribuintes, retroagindo a 2015, para mensurar o efeito da metodologia. Observou-se um aumento nos valores, com pico em 2019, ano de implementação da metodologia, conforme demonstra a Figura 5. Analisando o período de 2015 a 2018, anterior à aplicação da metodologia, o ISS médio pago foi de 7.732.552,89 reais. No período de 2019 a 2022, o valor médio foi de 11.422.897,19 reais, representando um aumento de 48% na arrecadação.
Gráfico 5 – ISS pago
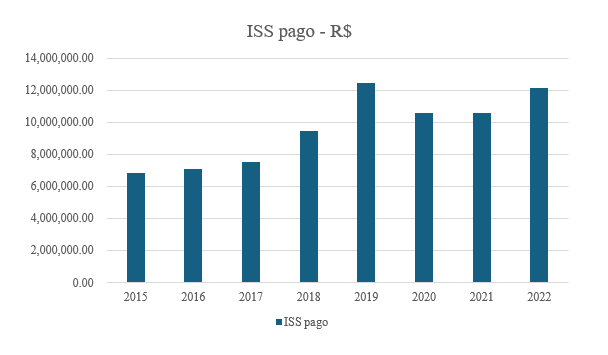
Fonte : Elaborado pelos autores (2024).
5. Conclusões
Na área da administração pública, a IA pode aprimorar as auditorias. Existe um grande volume de contribuintes e notas fiscais cuja análise manual exige um trabalho extenso. Alguns contribuintes se aproveitam dessa dificuldade para sonegar o NFS-e (notas fiscais eletrônicas). Consequentemente, há uma demanda por soluções que automatizem a análise de grandes volumes de dados, acelerando as decisões e tornando as ações tributárias mais eficazes, aumentando assim a arrecadação de impostos.
Os estudos relacionados baseiam-se em soluções manuais e em conjuntos de dados não representativos. Não foram encontrados estudos que se concentrem na detecção de fraudes por meio do uso indevido de taxas de impostos e que se baseiem na análise da frequência de termos NFS-e.
Neste trabalho, técnicas de PLN foram aplicadas aos textos descritivos de 38.727.247 NFS-e da Prefeitura de São Paulo no período de 2019 a 2022. Foram identificados os termos mais frequentes utilizados para detalhar serviços tributados com alíquotas mais altas, mas aplicados a NFS-e com código de serviço de alíquota mais baixa.
A descoberta desses termos possibilitou a identificação de contribuintes que emitiam documentos NFS-e fraudulentos, permitindo o agendamento eficiente de ações de auditoria. Isso resultou em maior eficácia das ações de fiscalização, atingindo uma taxa de pagamento de 72% para notificações de infração. Um grande volume de documentos NFS-e foi analisado e um número crescente de pagamentos do ISS foi verificado durante o período em análise. A adoção de PLN (Processamento de Linguagem Natural) e de uma infraestrutura de Big Data acelerou a detecção de fraudes e impulsionou a arrecadação.
Em trabalhos futuros, pretendemos aplicar técnicas de Aprendizado de Máquina (Mitchell, 1997) aos dados obtidos com PLN para classificar o NFS-e. Essa abordagem poderá gerar resultados mais promissores do que os obtidos neste estudo em termos de eficácia das operações de verificação, precisão das notificações de infração e aumento da arrecadação tributária.
Referências
APACHE HADOOP. O que é o Apache Hadoop? Site. Disponível em < https://hadoop.apache.org/ >. Acesso em 08/02/2024. Elaborado em 2006.
DARRAZÃO, E.; AMORIM V.; OLIVEIRA, K.; Gomes-Jr, L. Engenharia e avaliação de recursos para extração de informações em faturas. In: Anais da XVIII Escola Regional de Banco de Dados. SBC, 2023. pp. 80-89.
FELDMAN, R.; SANGER, J. Manual de Mineração de Texto: Abordagens Avançadas na Análise de Dados Não Estruturados. Cambridge University Press, 2006.
JUPYTER. Documentação do Projeto Jupyter. Site. Disponível em https://docs.jupyter.org/en/latest/ . Acesso em 09/02/2024. Preparado em 2015.
JURAFSKY, D.; MARTIN, JH. Processamento de Fala e Linguagem: Uma Introdução ao Processamento de Linguagem Natural, Linguística Computacional e Reconhecimento de Fala. 2ª ed . EUA: Prentice Hall PTR, 2008.
MACHADO, a. Guia passo a passo para criar um cluster Hadoop com 3 nós. Artigo disponível em < https://blog.4linux.com.br/hadoop-cluster/ >. Acesso em: 15/02/2024. Elaborado em 06/06/2017.
MANNING, CD; SCHÜTZE, H. Fundamentos do Processamento Estatístico da Linguagem Natural. Cambridge, MA: MIT Press, 1999.
MARINE, MC. Estratégias computacionais baseadas na similaridade de textos e visualização exploratória para a identificação de inconsistências em faturas eletrônicas. Monografia. Departamento de Ciência da Computação, Universidade de Brasília, 2023.
MITCHELL, TM Aprendizado de Máquina. Nova York, 1997.
NUNES, F. de HP; DELGADO, J. de S. A utilização da Inteligência Artificial pelas Administrações Fiscais. Revista Tributária e de Finanças Públicas, v. 155, N.30, p.73–86, 2023.
RECEITA FEDERAL DO BRASIL. Portal da Nota Fiscal Eletrônica. 2024. Disponível em:< https://www.nfe.fazenda.gov.br/portal/sobreNFe.aspx?tipoConteudo=PEhYdxncZBE=&AspxAutoDetectCookieSupport=1 >. Acesso em: 07 fev. 2024.
SANTOS, MTM Classificação de produtos em notas fiscais eletrônicas utilizando descrições textuais não estruturadas. Monografia. Instituto de Computação da Universidade Federal de Alagoas, 2022.
SAS. Big Data: O que é e por que é importante. 2024a. Disponível em: < https://www.sas.com/pt_br/insights/big-data/what-is-big-data.html >. Acesso em: 15 de fev. de 2024.
SAS. Hadoop: O que é e por que é importante. 2024b. Disponível em: < https://www.sas.com/en_us/insights/big-data/hadoop.html >. Acesso em: 15 de fev. de 2024.
SOUZA, AMA; SADDY, A.; SEYLLER, ADM; BERARDINELLI, AL; ARAÚJO, CM; SOUZA, DAVG; PESSANHA, DP; COIMBRA, EM; LÔBO, FLA; TEIXEIRA, G.; SOUSA, PRESUNTO; TORRES, IM; CAMPOS, A.; SILVA, JE; PEREIRA, JSSS; GALIL, JVT; ARGENTO, JRO; PINTO, JÓ; FREIRE, K.A; SILVA, LFB; PEIXOTO, LB; SILVA, LC Jr.; DAHER, LESLT; SILVA, MAM; TEMER, M. C.; TEIXEIRA, RLCJ; STRAUCH, TSR; SOUZA, WVS Inteligência Artificial e Direito Administrativo. Centro para Estudos Empírico-Jurídicos (CEEJ), 2022.
STEEDMAN, M. Processamento de linguagem natural. San Diego: Academic Press, 1996.
TECHVIDVAN. Integração Hadoop Spark: Guia Rápido. Artigo disponível em < https://techvidvan.com/tutorials/hadoop-spark-integration/ >. Acesso em: 15/02/2024.
Texto publicado originalmente em inglês/espanhol no Portal do CIAT, em 17 e 18 de junho de 2025, traduzido via Google Translator, com breves ajustes ortográficos. No original é citado a palavra “fatura”, na tradução usamos “nota fiscal”.
- https://www.ciat.org/ciatblog-procesamiento-de-lenguaje-natural-en-la-deteccion-de-fraudes-en-facturas-del-municipio-de-sao-paulo-parte-1/
- https://www.ciat.org/ciatblog-procesamiento-de-lenguaje-natural-en-la-deteccion-de-fraudes-en-facturas-del-municipio-de-sao-paulo-parte-2/
Aviso Legal disponibilizado no site do CIAT em relação ao texto publicado. Os leitores devem estar cientes de que as visões, pensamentos e opiniões expressas no texto pertencem exclusivamente ao autor e não necessariamente ao seu empregador, organização, comitê ou outro grupo ao qual o autor possa estar associado, nem à Secretaria Executiva do CIAT. O autor também é responsável pela precisão e exatidão dos dados e fontes.






